QCSG
The Quantum Computing Survival Guide
Written by River Way
QCSGWritten by River WayChapter 3: Quantum Circuits3.1 Definition of a GateQuantum GatesRecovering Angles from Vector Representation3.2 Rotation GatesCommon GatesFloating Point Rotations3.3 Alternate AxesThe Hadamard AxisArbitrary Axes3.4 Quantum RegistersQuantum CircuitsMatrix Tensor Product3.5 Controlled GatesControlled Not GateSWAP GateControlled Z GateControlled U GateCircuit Specifications3.6 Quantum ProgrammingQiskitQ#Cirq3.7 Case Study: Google's Quantum SupremacyQuantum vs. ClassicalIBM's Rebuttal
Chapter 3: Quantum Circuits
We have begun discussing the process of transforming a qubit, but we do not have a concise notation to describe many sequential transformations. This chapter will introduce the concept of quantum circuits, a quantum analogue to classical circuits. Quantum circuits are a widely used system of notation used to describe operations on the quantum state.
3.1 Definition of a Gate
Classical computers perform all of their operations through logic gates. What are gates? An in abstract sense, a gate is simply a boolean function which maps input boolean variables to output boolean variables .
In computer science, we can represent any boolean function with a truth table which contains rows, one for each possible combination of inputs.
The above truth tables describe four common classical logic gates seen in computer science. A set of gates is said to be universal if every boolean function can be implemented using a sequence of gates only inside the set. One such set of universal gates is {AND, OR, NOT}, but there are many universal sets. The set {NAND} is a universal set which only contains one gate inside, which is the AND gate followed immediately by the NOT gate.
Quantum Gates
Gates are some operation which acts on the input to produce an output. Quantum gates follow that same definition by operating on a quantum state to produce a different quantum state. However there are some characteristics which are required for a quantum gate to be valid. First, recall our notation to describe a quantum state of 1 qubit:
Since our quantum state is just a vector, a quantum gate is a matrix which acts on our quantum state through matrix-vector multiplication. Specifically, the gate is a square matrix whose size is equal to the quantum state. A gate acting on our 1 qubit system is a 2x2 matrix with complex entries. Another requirement for quantum gates is that their matrix needs to be unitary. A unitary matrix has the property that its adjoint (conjugate-transpose) is the same as its inverse.
The conjugate transpose was introduced as a method of converting between kets and bras in Dirac notation. Another property of these gate matrices is that all of the columns and rows are orthonormal. This means the absolute value of the determinant is 1.
Since every quantum gate is unitary, that means it is also reversible. Consider some sequence of quantum gates . The result of applying the sequence can be converted back into the original state by applying the adjoint of each in reverse order:
The transformations to the Bloch sphere discussed in the previous chapter can be described with quantum gates, except for collapse. The process of measuring a qubit cannot be expressed as a 2x2 unitary matrix since it collapses the quantum state into classical data. Since collapse is not reversible, we need to measure an infinite number of qubits to perfectly reconstruct the quantum state.
Recovering Angles from Vector Representation
In the following sections, we will be discussing quantum states in their vector forms since the ket forms are notationally verbose. Converting between the coordinates of the Bloch sphere and the vector representation of the qubit is common when working with computer programs. It can valuable to learn the different data types used for containing a qubit's data and how to convert between them. Starting with complex numbers, they can either be stored in Euclidean or polar form:
The function is a perfect inverse trigonometric function which returns the angle from the position X axis to the point defined by and . Traditional inverse trigonometric functions have domain restrictions which make them difficult to use in programs. Our function can be defined a number of ways, but we will use:
The denominator inside the function can be disregarded if it is assumed that and are distance away from the origin.
Typically our quantum state vector will hold Euclidean complex numbers since they are the easiest to work with in programs. Our first step to convert the vector contents to polar complex numbers:
Now we can easily calculate our spherical coordinates using our polar complex numbers:
The phase needs to be calculated as the difference between the polar angles because of the qubit's global phase. Recall that every amplitude of a quantum state can be multiplied by and there will be no observable changes. We choose to set so the first amplitude is real. Many quantum gates change a quantum state's global phase, so we cannot assume will always stay real without manually setting it.
3.2 Rotation Gates
Quantum gates can be described by unitary matrices acting on our vector representation of a quantum state. The rotations around the Bloch sphere also have matrix forms, as shown below.
These gates are known as the Rotation Operators and form the foundation for all single qubit transformations. Every other single qubit gate can be expressed as a combination of these three gates. Technically, only 2 of the 3 are necessary because one can be expressed from the other two. For example, an X rotation can be decomposed into:
The special case when produces the set of Pauli Gates shown below. Another common system of notation for the Pauli gates is .
All of the Pauli gates are their own inverse, which means:
When all three of the Pauli matrices are multiplied together, it produces the identity matrix, except for the scalar attached in front. The is a global phase! This global phase is the same reason that the Pauli X and Y gate differ from what the rotation gate produces when :
Global phase can apply to a quantum gate as well, this means different matrices can perform the same operation. The gates and are equivalent if they can be expressed as for some value .
Common Gates
Here are some common gates and their adjoints which appear in quantum computing literature:
A rotation matrix's adjoint is equivalent to rotating clockwise instead of counterclockwise. That is to say, , since rotating one way by and then immediately rotating the other way by will produce an identity operation.
Floating Point Rotations
Classical computers don't always store precise values. For a value like , it would require an infinite number of bits to perfectly represent. Instead, classical computers store estimations using a fixed number of bits which are called floating point numbers. It may not be possible to rotate around the Bloch sphere by an arbitrary amount with perfect precision, so we will have to use approximations.
The Solovay-Kitaev Theorem implies any single qubit gate can be approximated using gates from a finite set. The value is a small constant, roughly 2. The minimum possible value of has not been proven. The value represents how accurate the approximation is. Since our rotation gates take the parameter, any set containing the rotation gate will be infinite. An example of a finite set would be where the parameter is constant for every gate in the set. The only requirement for the finite set is that it must fill .
If a finite set of gates fills , then for every pair of quantum states, there must exist some sequence of gates which links them.
The elements of the sequence do not need to be unique. This requirement of a filling set is not satisfied by all sets of gates. For example the set does not fill . In fact, no value of on a single axis will produce a filling set. This is because some quantum state will never be able to leave the ring generated by , so there are states which cannot be accessed.
Another example of a non-filling set is . This one is slightly deceptive because for some generic state , it appears to fill . However, consider the state . There are only 6 states which are accessible: two states for each axis where the axis intersects the Bloch sphere. Conversely, it is also impossible to transform a generic state into . Since there exists a state which cannot access every other state, this set does not fill .
Checking if a set fills can be reduced to a graph problem. Suppose there is an infinite graph with one vertex per quantum state, and each vertex as edges, one for each gate in the set. A vertex may have a loop, where an edge connects the vertex to itself. If the graph has two or more isolated subgraphs, then the set does not fill . Isolated subgraphs, also called components, are a collection of vertices which cannot be connected to the rest of the graph.
This theorem is very important because it allows us to create arbitrary rotations out of a finite set of gates, and do it efficiently. Physical implementations of quantum computers may only be able to use certain fixed gates due to the immense engineering challenges present in building the hardware. Certain methods of error correction do not work for the continuous rotation gates, so approximating them from a finite set is required.
3.3 Alternate Axes
We have discussed rotating around the three major axes: X, Y, and Z. However, there is no reason why we can't rotate around other axes. A minor axis is a line defined by the origin and a single point. Technically, the data representing an axis is the same as the quantum state, since it is just a vector. For example, consider the axis which is defined to be . This is a unit vector which lies in the plane, it represents the line where . Just like the major axis rotations, there is also a matrix for rotating around the axis:
The matrix for when is:
Although the axis is not frequently seen in quantum computing literature, it provides a nice example of a minor axis rotation matrix.
The Hadamard Axis
The Hadamard Gate, denoted , is one of the most common gates used in quantum computing, and it performs the following operation:
The Hadamard gate is synonymous with generating superposition because it transforms both basis states into equal superposition. The state is mapped to the positive X axis and the state is mapped to the negative X axis. This operation is exactly what is performed by beam splitters. A beam splitter is a half-silvered mirror which will split an incoming stream of photons, reflecting one stream and letting the other stream pass through.
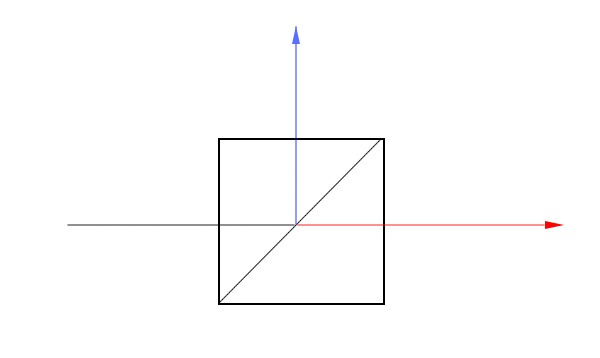
In the above diagram, the beam of light is coming from the left and splits into two separate beams. The half-silvered mirror is placed diagonally in the box. We can place two beam splitters and two mirrors in a configuration called a Mach-Zender Interferometer and add detectors for each of the projected output beams.
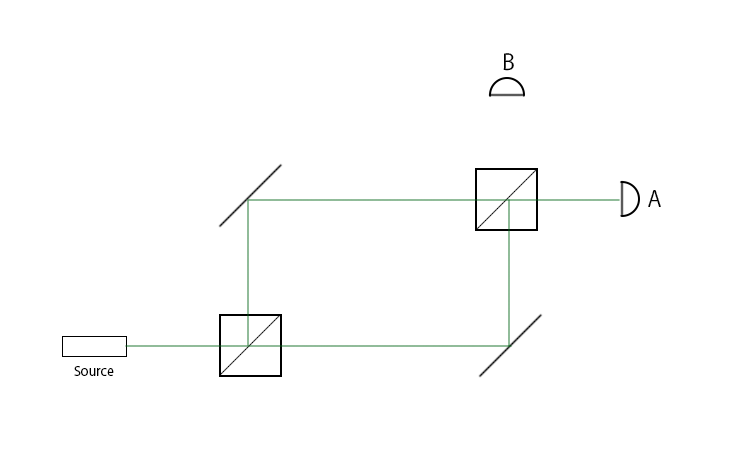
Using the configuration of beam splitters and mirrors described above, say we produce 100 photons. How many of those photons will be detected by B?
The answer is zero. All of the photons will be detected by A, the detector at B will never see a photon. This result seems unintuitive, if a beam splitter splits a stream of photons, why doesn't the second half-silvered mirror split both streams again? This is because . In this experiment, the photon acted as a qubit, initialized to the state . After passing through the first beam splitter, the qubit entered superposition, but came back out of superposition after the second beam splitter. The Hadamard gate's matrix representation is:
The gate can be decomposed into . Specifically, the Hadamard gate is a rotation of around the Hadamard axis, . The axis is a line in the plane where . Just like the axis, there is a matrix which generalizes a rotation of any amount:
These beam splitters are more than neat party tricks. Using the KLM Protocol, it is possible to create universal quantum computers using just mirrors, half-silvered mirrors, and phase shifters.
Arbitrary Axes
The next step is to rotate our quantum state around any arbitrary axis. This is an applet which shows the accessible state space of rotating the state around any axis. The sliders on the left change the and of the quantum state and the sliders on the right change the and of the axis. The axis is set to the Hadamard axis by default.
The matrix for rotating around any axis can be written as the sum of the identity matrix and the Pauli matrices:
This is the equation used to derive the rotation around the and axes described above. Alternatively, the same matrix can be written as the product of the and rotation matrices:
Note how the sum equation uses the axis' Euclidean coordinates and the product equation uses the axis' spherical coordinates.
Since a quantum state is mathematically equivalent to a vector, that implies we could use a quantum state as an axis to rotate around. For example, rotating around itself is always an identity operation:
However, we don't actually know the and of some generic quantum state. To rotate around an axis, the coordinates of the axis must be known, otherwise how would we know which gates to apply?
3.4 Quantum Registers
Up to this point, we have used the term quantum system interchangeably with the term qubit because we have only focused on a single qubit. However, a quantum system is a more general concept, it refers to all quantum objects of interest to us in a particular setting. When we have collection of qubits, it is called a quantum register and they are grouped together under one quantum system.
Above is an example of a two qubit quantum system in equal superposition. The is still used to describe the entire quantum register, although now there are more basis states. Rather than just having and , there are now four basis states to describe every possible combination of states the qubits could collapse into. Each basis state also has a complex coefficient assigned to it, the probability of the quantum system collapsing into a particular basis state can be found: . In general, a quantum register of qubits can be described in ket notation:
Suppose we are given two separate qubits, how do we create our quantum system to describe both of them?
The key to merging two separate qubits into one quantum system is the tensor product. This operation is denoted by the symbol and it looks similar to distributing two binomials. There are different notations for the tensor product, but they all mean the same thing:
We have described how the tensor product works using the Dirac notation, but quantum states can also be described using vectors:
In general, a tensor product between a vector with rows and another vector with rows produces a vector with rows. The tensor product is associative, but it is not communitive, so . For this reason, we need to be clear about the ordering of the qubits. The standard convention is to have the rightmost qubit be the least significant bit. This means the state will represent the number 4 instead of the number 1. Since the quantum state is being created from an array of qubits, the indexes follow zero-based numbering. The least significant qubit is described as the zeroth qubit in the register.
Here is an algorithm which will create the amplitude at index after the tensor product of qubits:
def create_amplitude(row_index, qubits): amplitude = 1 for i in n: if ((row_index & 1 << i) == 0): amplitude *= qubits[i].alpha else: amplitude *= qubits[i].beta return amplitudeConsider the index in a 5 qubit register. The amplitude at this position is . Each in the index corresponds to the amplitude being multiplied by that qubit's component and each means the amplitude is multiplied by that qubit's component.
The algorithm above iterates through each bit in the index and multiplies the amplitude by the corresponding component depending if the bit is or . This algorithm uses bitwise operators to determine the state of a bit inside the index. The following bitwise operators are frequently used:
&- Bitwise AND|- Bitwise OR^- Bitwise XOR<<- Bitwise left shift>>- Bitwise right shift
Quantum Circuits
When describing which gates are being applied to which qubits, using the Dirac notation can become cluttered. Quantum circuits are a visual way to show the ordering of the gates. Below is an applet to show a simple quantum circuit with 2 qubits and an X, Y, and Z rotation gate on each.
Starting from the left, first there are the inputs to the quantum circuit. Typically, a quantum circuit is initialized with for each qubit, but sometimes a generic state is the input when comparing multiple circuits. The top qubit is the least significant qubit which corresponds to the rightmost qubit in the Dirac notation.
Next are all of the gates in the circuit. Each wire runs horizontally and contains a sequence of gates which are applied to the qubit. Unlike the matrix form of gates, the gates in a circuit are read left-to-right. In our simple circuit, the X gate is applied first, followed by the Y gate and then the Z gate. For this example, each gate has a slider which controls the parameter of that gate.
The square on the right side is a visual representation of the quantum state. Each sub-box represents a basis state, the size of the circle represents the magnitude and the orientation of the circle represents the phase. The global phase is automatically adjusted so the state remains real.
This example is just a simple quantum circuit for demonstration purposes. A more advanced quantum circuit builder is available through Quirk.
Matrix Tensor Product
A 2-qubit quantum system can be created by using the tensor product on two vectors. How do we apply a gate to this larger vector? Our matrices cannot be directly applied to a vector with rows, there would be a dimension mismatch. The key is to use the tensor product on the gate as well!
If we would like to apply a Hadamard gate on the right qubit and nothing on the left qubit, it is the tensor product between the and matrices. In general, a tensor product between two matrices takes the form:
The tensor product for matrices is still non-communitive. In order to apply a gate to the th qubit, there must be matrices tensored together:
When applying just one gate to a quantum register, it gets tensored with identity matrices. This fact highlights an interesting characteristic of the tensor product. Say we would like to apply two gates on a 2 qubit system, and . We could tensor the gates together like shown with the general form of the tensor product, but we could also tensor each gate with the identity matrix like shown with the th qubit form and then multiply:
Tensoring each matrix with the identity matrix and them multiplying them together is equivalent to tensoring the matrices together directly. Furthermore, the matrix multiplication of and is communitive! This can be generalized to any number of gates acting on a quantum register, the matrix multiplication between all of these identity-tensored gates is communitive.
3.5 Controlled Gates
The goal of this section is to address how qubits interact with each other. So far, we have treated qubits as separate entities which can be operated on independently. To create a powerful model of computation, qubit states need to be able to impact each other. In quantum computing, we use transformations called controlled operations which are able to connect qubits.
Controlled Not Gate
The most fundamental controlled gate is called the controlled not and it takes in 2 qubits: a control qubit and a target qubit. In English, the transformation a controlled not (CNOT) gate performs is described as: if the control qubit is , then flip the target qubit. We can create a truth table which describes the operation if the left qubit is the control and the right qubit is the target
The above ket notation shows a truth table for every basis state. If the control qubit is , the CNOT acts as an identity operation and nothing happens. If the control qubit is , the target qubit is flipped. The same operation can be visualized in the tensored vector form:
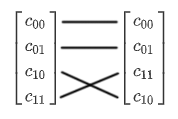
The CNOT transformation switches the placement of the and coefficients. The CNOT gate is also called the CX gate since it is essentially a controlled X rotation. The matrix form of the CNOT gate is written as:
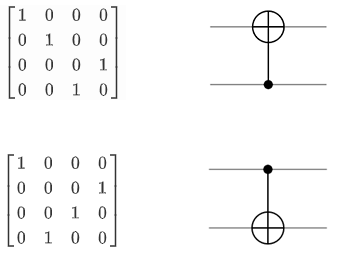
Notice how the transformation the CNOT applies changes depending which qubit is acting as the control. In circuit form, the small black dot denotes the control qubit and the large shows the target qubit. Remember that we are using the standard where the topmost qubit line is the least significant qubit. The truth table and the tensored vector descriptions are referring to the top circuit where the control qubit is below the target qubit. Some sources use a different standard where the bottom-most qubit is the least significant qubit, which would switch the matrix-circuit representations.
The control and target qubits cannot be the same qubit in a CNOT gate. Such an operation would create the following truth table, which is not reversible:
One question students often ask is "why use the symbol for the CNOT gate?" In computational logic, the symbol refers to the exclusive or (XOR) of two bits. The controlled-not gate is a reversible version of XOR, the control qubit is unaffected and the target qubit becomes the XOR of the control and the target:
SWAP Gate
An interesting property of the XOR operation is that it can swap the values of two variables without using a temporary variable. Consider the binary variables and and perform the following algorithm on them:
After 3 XORs, the variable will contain the original value of and vice versa. As we have already discussed, the CNOT gate is the reversible equivalent to the XOR gate, which means we can create a SWAP gate out of 3 CNOT gates:

This gate switches the incoming qubit states so the bottom qubit now contains the original state of the top qubit and vice versa. The SWAP gate is symmetric with respect to the qubits it is swapping. That is to say, . As expected, the SWAP gate is its own inverse, so two sequential SWAP gates is an identity operation. The matrix of the SWAP gate is:
Controlled Z Gate
Similar to how the CNOT gate is a controlled X rotation of , we can also create the CZ gate for a controlled Z rotation. The CZ gate performs the following operation:
The controlled Z gate applies a phase shift only when both qubits are in the state . This operation is symmetric with respect to the input qubits:
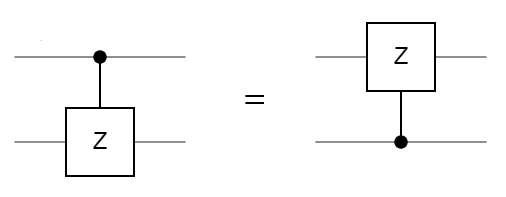
Since the orientation of the CZ gate doesn't matter, another common notation for the gate is to have control dots on both qubits. The matrix representation of the gate is:

A CZ gate can be constructed using a CNOT gate and 2 Hadamard gates like so:
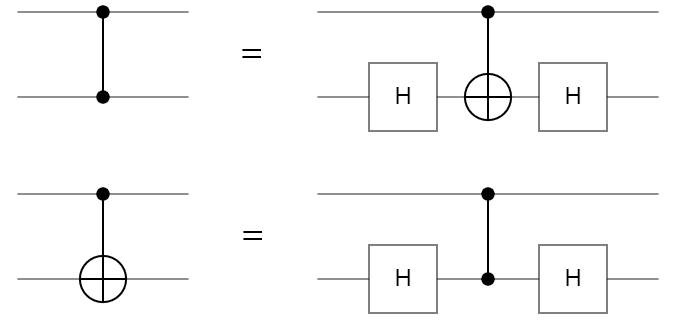
Using the above relationship, we can flip the CZ gate since it is symmetric and create a method to flip the CNOT gate using Hadamard gates.
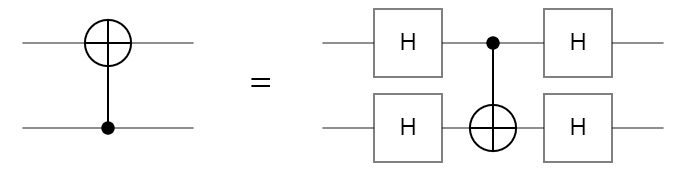
The controlled Z gate has applications in simulating quantum circuits on quantum computers. The runtime of simulating a CZ gate is faster than a CNOT gate, so if a circuit can be transformed into an equivalent circuit using approximately the same number of gates, the simulation will be noticeably faster.
Controlled U Gate
The controlled X and controlled Z gates are specific instances of the general controlled U gate. Any single qubit gate can be transformed into a CU gate:
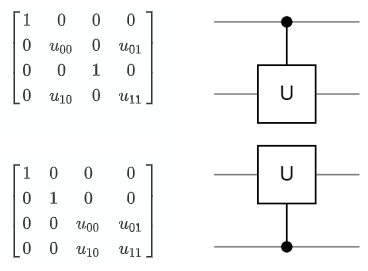
Every 2 qubit gate described above has acted on adjacent qubits inside the circuit. It is also possible to have the control further away and "jump over" qubits to reach the target. The CU gate does not impact the two qubits which do not have a control or gate placed on them. However, what if we have a constraint on our circuit that all 2 qubit gates must act on adjacent qubits? This can be overcome by simply using SWAP gates to pull the control closer:
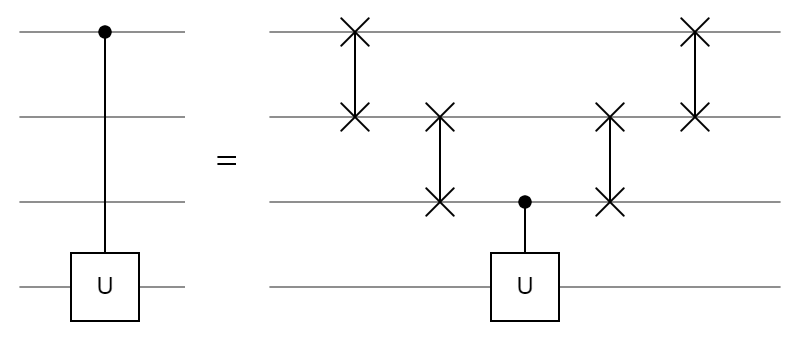
This idea can be extended for any number of intermediate qubits by increasing the staircase of SWAP gates. Engineering physical quantum computers is already a challenging task, creating controlled gates between any pair of arbitrary qubits in the circuit may be infeasible. As a result, this trick can be used so engineers only need to implement controlled operations between adjacent qubits in the circuit.
Circuit Specifications
In the above CU circuit, originally there weren't any gates on the middle two qubits. However, there are several gates acting on them after the transformation. In this circuit, the middle two qubits are acting as ancilla qubits. An ancilla qubit is a qubit which has operations performed on it that do not directly contribute to the result, but help indirectly. They typically come in two flavors: identity ancilla qubits and garbage ancilla qubits.
The ancilla qubits in the CU circuit are acting as identity ancilla qubits because even though there are gates being applied to them, the end result is equivalent to the identity operation. These identity ancilla qubits were borrowed to accomplish a more complicated goal, but had the affects undone after the goal was accomplished. Garbage ancilla qubits do not have such restrictions, the results after measuring a garbage ancilla qubit are discarded. Garbage ancilla qubits are particularly useful in quantum computation for reducing the depth of a circuit.
The depth of a circuit refers to how long it takes to run. This is measured by the number of timesteps a circuit has. In one timestep, several gates can be applied to the quantum register, but two gates cannot be applied to the same qubit in a single timestep. Many quantum circuits are extremely parallelizable since multiple gates are applied in sync. The depth of a circuit can change after a quantum complier changes the circuit to fit the architecture of the computer. For example, if our quantum computer can only apply two qubit gates to adjacent qubits, the CU circuit above transforms from having a depth of 1 to a depth of 5. This is similar to how classical programs change length after being compiled for a target machine. Typically, the actual depth of a quantum circuit is not used, just the asymptotic gate depth. It is expressed using big-oh notation as a function of the input. For example, linear gate depth would be .
3.6 Quantum Programming
After discussing the operations a quantum computer can perform to its qubits, how would we program a quantum computer? To date, a high-level quantum programming language has not yet been developed so modern quantum computers are coded with individual gates, similar to assembly for classical computers. There aren't even any independent quantum languages, most of the "languages" are just libraries accessed from classical languages.
Modern quantum programming workflow first creates a desired circuit in a quantum programming library on a classical computer. Then that circuit is sent to either a quantum computer or a quantum simulator to run. After, the result of the computation is returned to the user, typically as a histogram of measurement results. This histogram is now considered classical data and the user can use it as they please.
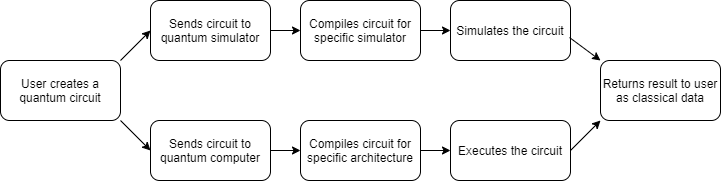
The compilers are a very important step in this process which often get overlooked. Just like classical compilers, a quantum compiler takes in some general circuit and changes the gates to run most effectively on the target platform. The platform can be a specific architecture or simulator type which handles certain types of circuits better than others.
There are many libraries used for creating quantum circuits, most companies have developed their own so it is likely there won't be a standard one until quantum computers become more ubiquitous.
Qiskit
Released in March of 2017, Qiskit is IBM's quantum computing framework for Python. Users can create circuits and use a range of tools examine them. Qiskit comes with four components: Terra, Aer, Aqua, and Ignis. Terra is element used to build circuits and send them to a real quantum computer over the cloud. Aer is a quantum simulator which can model a perfect or imperfect quantum computer. Aqua is a package of premade algorithms usable without understanding of quantum computing. Ignis is a collection of tools for understanding noise. Qiskit is the most used framework among the quantum computing community and is the one used in this document for describing circuits with code.
Q#
Released in December of 2017, Qsharp is Microsoft's quantum computing framework for C#. Currently, Q# is just a quantum simulator capable of processing up to 32 qubits on a local machine and up to 40 on Microsoft Azure, their cloud computing service. The community surrounding Q# expects Microsoft to eventually offer a hardware service similar to Qiskit using topological qubits. Topological qubits are a currently theoretical implementation of a qubit which is still under development.
Cirq
Released in July of 2018, Cirq is Google's quantum computing framework for Python. Similar to Q#, Cirq is just a quantum simulator with no currently announced plans of offering a physical backend to run circuits. Cirq has close ties with Google's OpenFermion project which uses quantum algorithms to simulate fermionic systems like quantum chemistry.
3.7 Case Study: Google's Quantum Supremacy
In late 2019, Google announced they had achieved quantum supremacy on their 53 qubit quantum processor named Sycamore, published in Nature. Quantum supremacy is the term for when a quantum program can beat a classical program at a task. What kind of task? It doesn't matter. There is no official benchmark, so the task can be any type of algorithm or can simply have a useless objective. As long as the QPU is significantly faster than a classical computer at any objective, quantum supremacy is declared.
What task did Google use to have their quantum computer compete in? Simulating a quantum computer. Sycamore is a quantum computer, so the simulation is just running a quantum circuit. So as long as the quantum computer can run faster than a classical computer can simulate it, the quantum computer wins. This may appear rather silly since there isn't really any objective to the computation, but that is actually why it is clever. If there was an objective to compute then there would be alternative methods for a classical programmer or patterns to exploit to make the classical program faster.
Specifically, Google called this task random circuit sampling. Every quantum circuit creates a probability distribution, so the objective was to find the probability distribution of a randomly generated circuit. A random circuit does not have any patterns for a classical programmer to use for time or memory exploitations. However, not all quantum circuits take the same amount of time to simulate. The hardest circuits for a classical simulator are random and all the qubits are highly entangled (but not maximally entangled)!
There are limitations on the quantum computer as well. The Sycamore processor is noisy, every gate applied causes small errors to build up and can lead to the wrong answers if too many gates are applied. So the ideal circuit should have the following properties:
- No observable patterns
- Highly entangled
- Small depth
To create circuits that have all three properties, the Google quantum team used a pseudorandom generator which uses a seed to create circuits in this format:
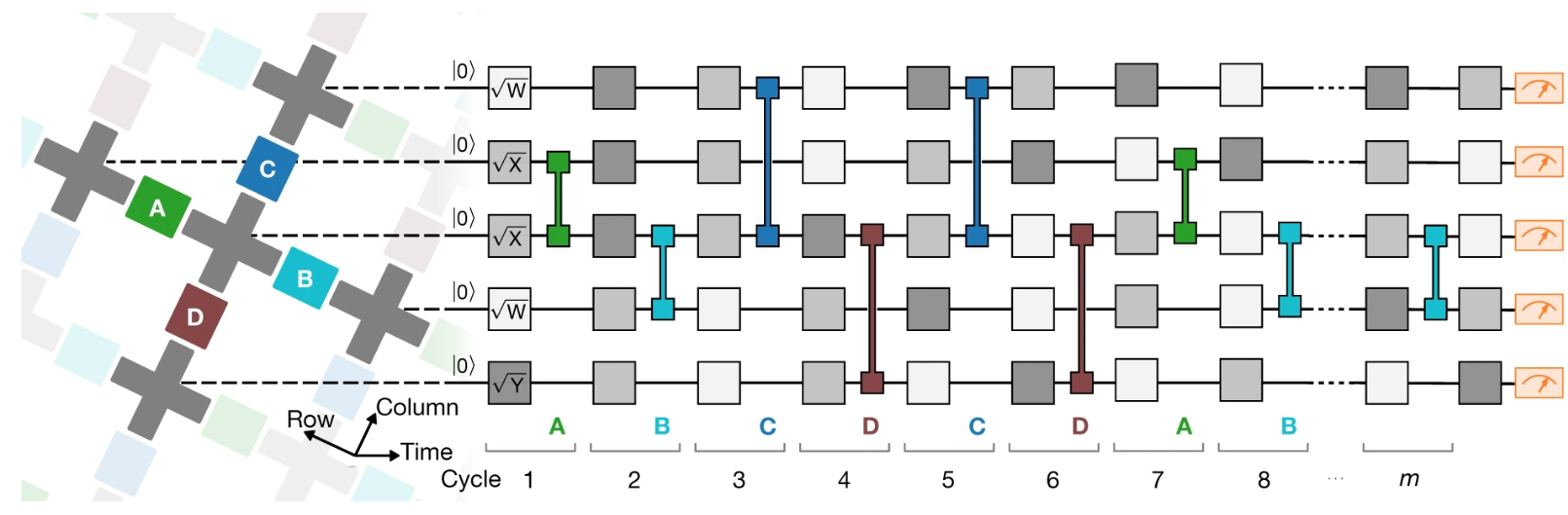
The circuit is divided into m cycles in which every cycle has 1 single qubit gate applied per qubit followed a double qubit gate. The single qubit gates are chosen pseudo randomly and can be , , or . Two gates of the same axis cannot be chosen sequentially. The gate is a rotation of radians around the axis . Similar to the Hadamard axis, this axis is formed by the line when . The double qubit gates are chosen from a set sequence: repeat . The chosen letter represents the gate being applied to every pair of neighbor qubits connected by a colored coupler.
To understand the double qubit gates better, we can look at Sycamore's qubit layout. In figure 4.5.2, the gray crosses represent qubits and the colored boxes are couplers which connect the qubits together. The outlined cross on the top row is a qubit which does not work which is why this QPU is only 53 qubits instead of the original 54. When a double qubit gate is chosen from the set, for example , all of the green couplers activate at the same time. So the double qubit layer in the circuit does not just refer to one pair of qubits; it refers to all pairs of qubits joined by a green coupler. Not every qubit is affected by the gate however, since the bottom row does not have any green couplers connecting to them.
Quantum vs. Classical
Every quantum circuit essentially creates a probability distribution, but the way a quantum computer finds this distribution is different than a classical computer. A quantum computer approximates the distribution by running the circuit many times and recording the result of each measurement. After taking a large number of samples, the sampled distribution is roughly equal to the real distribution. Google's team sampled their largest circuit 30 million times, taking around 100 minutes.
Google's team used a Schrödinger/Feynman hybrid algorithm to simulate a 43 qubit circuit on a classical computer. The Schrödinger algorithm stores all coefficients in memory and the Feynman algorithm calculates each coefficient independently which only requires a polynomial amount of memory, but requires exponentially more time proportional to the depth of the circuit.
In their paper, the team made the claim that using this hybrid algorithm to simulate the largest 53 qubit circuit would take 10,000 years on the world's best supercomputers, thus proving quantum supremacy. This time estimate was created by assuming the memory was constrained to Random Access Memory (RAM). Other experts did not agree with this assumption.
IBM's Rebuttal
The quantum computing team at IBM responded to Google's claim to quantum supremacy by using a pure Schrödinger algorithm. They showed that it was possible to rotate the memory for the quantum state out to disk, only keeping the active parts in RAM. Every coefficient is 8 bytes since they are complex numbers, stored as two single precision floating point numbers. The quantum state is = 64 petabytes. That size is certainly large, but not unachievable by modern computers. IBM's team used a host of performance enhancing techniques to perform the simulation in 2.5 days.
By definition, Google's team still technically proved quantum supremacy since the quantum computer ran faster than the classical simulation (100 minutes < 2.5 days), even if it wasn't by their predicted margin of 10,000 years. However, due to the exponential nature of simulating quantum computers, a 100 qubit quantum state would take 9,000,000,000,000,000 (9 quadrillion) petabytes to store. This amount of memory is simply unachievable by modern or near future computers. Even if a 53 qubit processor strikes controversy over if it deserves quantum supremacy or not, 100 qubit processors will be developed in the near future and the outcome will be clear.
One incredibly important point brought up in IBM's response is the entire concept of quantum "supremacy". The nature of quantum processors are to be devices which coordinate with classical computers, not compete against them. The notion of claiming quantum supremacy is no less ridiculous than claiming "GPU supremacy" because a GPU was shown to be faster at one specific task. The term quantum supremacy was blown out of proportion by the media and broadly misunderstood by the general public.